Knowledge Evolution in Neural Networks
CVPR Oral 2021
Ahmed Taha Abhinav Shrivastava Larry Davis
University Of Maryland - College Park
Abstract
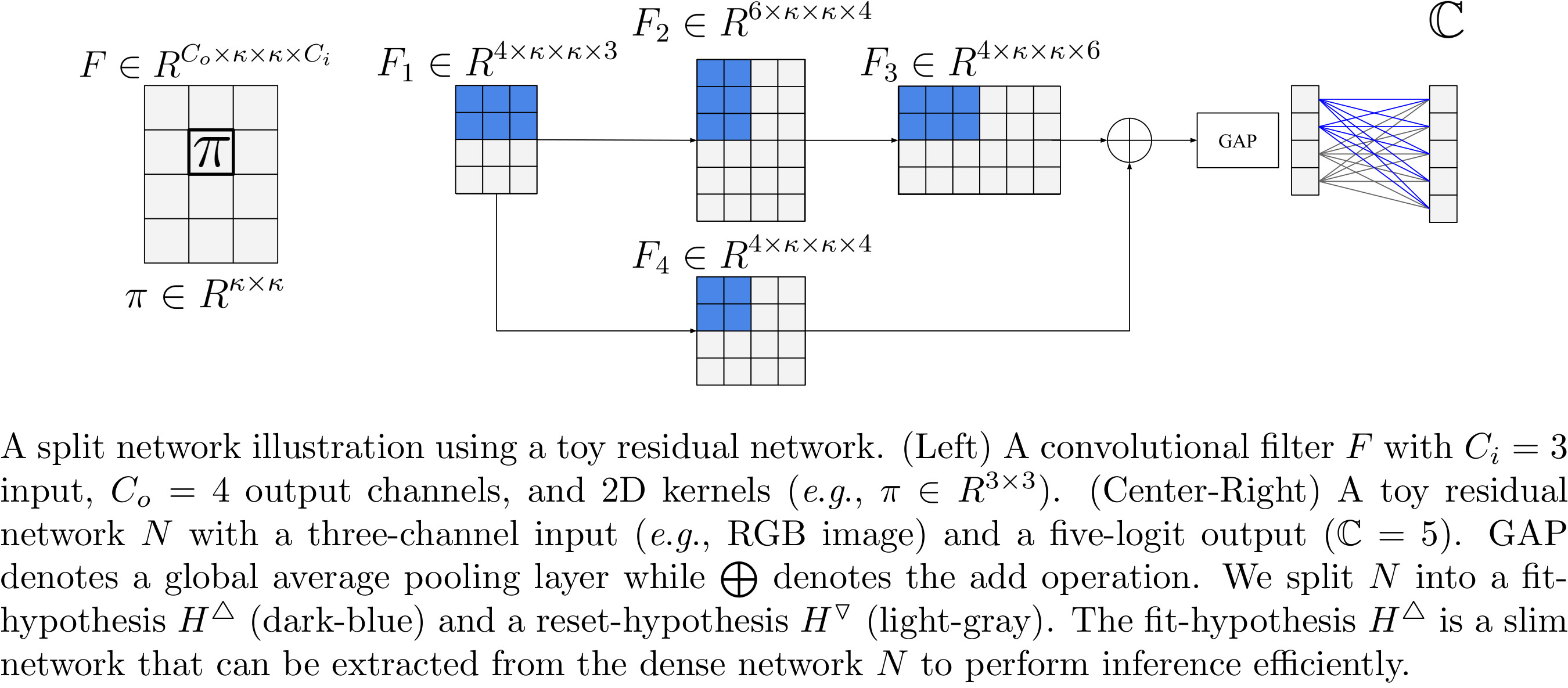
Deep learning relies on the availability of a large corpus of data (labeled or unlabeled). Thus, one challenging unsettled question is how to train a deep network on a relatively small dataset? To tackle this question, we propose an evolution-inspired training approach to boost performance on relatively small datasets. The knowledge evolution approach splits a deep network into two hypotheses: the fit-hypothesis and the reset-hypothesis. We iteratively evolve the knowledge inside the fit-hypothesis by perturbing the reset-hypothesis for multiple generations. This approach not only boosts performance, but also learns a slim (pruned) network with a smaller inference cost. Knowledge evolution reduces both overfitting and the burden for data collection. We evaluate the knowledge evolution (KE) approach on various network architectures and loss functions. We evaluate KE using relatively small datasets (e.g., CUB-200) and randomly initialized deep networks. KE achieves an absolute 21% improvement margin on a state-of-the-art baseline. This performance improvement is accompanied by a relative 73% reduction in inference cost. KE achieves state-of-the-art results on classification and metric learning benchmarks.
Bibtex
@inproceedings{taha2021knowledge,
title={Knowledge Evolution in Neural Networks},
author={Taha, Ahmed and Shrivastava, Abhinav and Davis, Larry},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2021}
}
Acknowledgements
This work was partially funded by independent grants from Facebook AI and DARPA SAIL-ON program (W911NF2020009)